

TM Data School – Để thực hiện tốt các công việc liên quan đến truy vấn, xử lý và tổ chức dữ liệu, windows functions là tập hợp các hàm vô cùng quan trọng trong trong SQL giúp xếp hạng, thực hiện các phép toán mà bạn bắt buộc phải nắm chắc.
Cùng TM tìm hiểu Window Functions là gì và cách sử dụng Window Functions trong bài viết sau nhé!
Đọc thêm: Hướng dẫn tự học và các nguồn SQL để luyện tập dành cho người mới bắt đầu
1. Window Functions là gì?
Windows functions trong SQL là các hàm được sử dụng để thực hiện các phép tính các dòng theo một điều kiện gom nhóm.
Khác với các hàm aggregate thông thường khi kết hợp với GROUP BY sẽ trả về kết quả tính toán tất cả với các dòng theo nhóm (cột) được GROUP BY, trong khi các hàm aggregate trong window functions sẽ trả về kết quả tính toán theo từng dòng.

Ví dụ:
Cho một bảng job_salary chứa dữ liệu của các vị trí công việc và mức lương của từng vị trí theo cấp bậc kinh nghiệm.
Khi kết hợp GROUP BY trên cùng một đối tượng (hoặc nhóm đối tượng), ví dụ: tính mức lương trung bình của từng vị trí công việc,… kết quả sẽ gom nhóm và trả về số lượng dòng tương đương số lượng của đối tượng (hoặc nhóm đối tượng) đó, trong ví dụ này là số lượng vị trí.
Nhưng nếu cần tính toán trên những đối tượng khác nhau (giả sử vừa cần hiển thị mức lương theo vị trí công việc, vừa cần tính mức lương trung bình của các vị trí tương tự nhau) và cần hiển thị theo từng dòng, GROUP BY sẽ rất phức tạp vì cần tính toán hai nhóm riêng và sử dụng JOIN để kết hợp. Lúc này, sử dụng window functions sẽ gọn gàng hơn và kết quả sẽ hiển thị thêm một cột mới trong bảng ban đầu.
Đọc thêm: GROUP BY là gì? Tìm hiểu về câu lệnh GROUP BY trong SQL
Syntax của Windows Functions:
Windows Functions () OVER (
[PARTITION BY partition_expression, … ]
ORDER BY sort_expression [ASC | DESC], …)
Trong đó:
- PARTITION BY: dùng để nhóm các dòng có liên quan theo một điều kiện
- ORDER BY: dùng để sắp xếp các dòng có trong nhóm đó
2. Các loại Window Functions
Có thể chia window functions thành ba nhóm: Aggregate functions, Ranking functions và Value functions.

2.1. Aggregate Functions
Các hàm tổng hợp (aggregate) trong window functions có logic như các hàm tổng hợp phổ thông, được sử dụng để thực hiện các phép tính toán và tổng hợp theo một (nhóm) đối tượng cụ thể. Các hàm AGGREGATE bắt buộc phải có mệnh đề PARTITION BY trong OVER() nhằm xác định đối tượng để tính toán giá trị.
Một số hàm cơ bản bao gồm:
- AVG(): hàm tính giá trị trung bình
- COUNT(): hàm đếm số giá trị
- MAX(): hàm trả về giá trị lớn nhất
- MIN(): hàm trả về giá trị nhỏ nhất
- SUM(): hàm tính tổng các giá trị
Giả sử, bảng ms_employee_salary chứa dữ liệu về nhân viên, bao gồm tên, bộ phận và mức lương. Làm cách nào để so sánh được mức lương của mỗi nhân viên và mức trung bình của bộ phận?
Có thể giải quyết bài toán bằng truy vấn:
SELECT
department,
first_name,
salary,
AVG(salary) OVER (PARTITION BY department)
FROM employee;
Truy vấn này sẽ gom nhóm mức lương của tất cả nhân viên theo từng bộ phận và tính mức trung bình, sau đó hiển thị như một trường tính toán mới.

2.2. Ranking Functions
Các hàm RANKING được sử dụng để gán số cho các hàng tùy theo thứ tự xác định nào đó. Khác với các hàm AGGREGATE, các hàm RANKING bắt buộc phải có mệnh đề ORDER BY trong OVER().
Các hàm RANKING bao gồm:
ROW_NUMBER()
Hàm ROW_NUMBER() giúp đánh số thứ tự liên tiếp bắt đầu từ 1 cho tất cả các hàng trong nhóm, theo thứ tự được sắp xếp bằng ORDER BY và không quan tâm đến những giá trị giống nhau (Ví dụ: 1,2,3,4,5,…)
Giả sử, bảng google_gmail_emails chứa dữ liệu về email được gửi từ mỗi người dùng. Câu hỏi là làm thế nào để biết người dùng nào có số email gửi đi nhiều nhất?
Bài toán trên được giải với query:
SELECT
from_user,
COUNT() as total_emails, ROW_NUMBER() OVER (ORDER BY count() desc, from_user ASC)
FROM google_gmail_emails
GROUP BY from_user
Truy vấn này sẽ lấy thông tin về id của người dùng, đếm tổng số email được gửi của mỗi người. Sau đó sắp xếp theo số lượng email từ nhiều tới ít và đánh số thứ tự, với những người dùng có cùng số lượng thì sắp xếp theo id người dùng thứ tự từ a tới z.

RANK()
RANK() xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và bỏ qua thứ hạng đó (Ví dụ: 1,1,3,4,5,…)
Với ví dụ trên, cả hai người dùng đầu tiên đều có tổng số 19 email. Vì vậy, nếu không có điều kiện khác (sắp xếp theo thứ tự bảng chữ cái) thì sẽ không biết người dùng nào cần được xếp hạng cao hơn.
Hàm RANK() giải quyết vấn đề bằng cách gán cùng một giá trị cho cả hai hàng:
SELECT
from_user,
COUNT() as total_emails, RANK() OVER (ORDER BY count() desc)
FROM google_gmail_emails
GROUP BY from_user
Truy vấn này sẽ đếm tổng số email của mỗi người dùng, sau đó đánh số thứ tự của những người dùng có lượng email từ nhiều nhất và giảm dần, hai người dùng có cùng số lượng emails sẽ đều được đánh cùng một số thứ tự và nhảy tiếp tới thứ hạng tiếp theo.

RANK() vẫn gán giá trị 3 cho user thứ ba vì phía trước đã có hai giá trị được xếp hạng và giá trị total_emails của nó khác với các user đó.
DENSE_RANK()
Hàm DENSE_RANK() xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và không bỏ qua thứ hạng đó và sẽ gán số liên tiếp giá trị cho hàng tiếp theo (Ví dụ: 1,1,2,3,4,…)
Với ví dụ trên, syntax của dense_rank() là:
SELECT from_user,
COUNT() as total_emails, DENSE_RANK() OVER (ORDER BY count() desc)
FROM google_gmail_emails
GROUP BY from_user

Do có hai người dùng có tổng cộng 19 email, hai người dùng này đều được gán cùng một giá trị xếp hạng. Tuy nhiên, trong khi hàm RANK() sẽ gán giá trị 3 cho user thứ ba thì DENSE_RANK() chỉ định thứ hạng 2 vì hàm không bỏ qua các thứ hạng chưa xuất hiện.
PERCENT_RANK()
Các giá trị xếp hạng trong trường hợp PERCENT_RANK được tính bằng công thức sau: (rank – 1)/ (row – 1). Trong đó: rank là thứ tự của giá trị đó (các giá trị giống nhau trả về thứ hạng giống nhau) và row là tổng số dòng (xét trong một partition). Tất cả các giá trị xếp hạng được chia tỷ lệ theo số dòng và nằm trong khoảng từ 0 đến 1. Ngoài ra, các dòng có giá trị đầu tiên luôn được gán giá trị xếp hạng là 0.
Với ví dụ trên, syntax của percent_rank() là:
SELECT from_user,
COUNT() as total_emails, PERCENT_RANK() OVER (ORDER BY count() desc)
FROM google_gmail_emails
GROUP BY from_user

Cách tính thứ tự xếp hạng được tính theo đúng công thức, ví dụ user thứ ba được tính percent_rank = (3-1)/(25-1) = 2/24 = 0,083.
NTILE()
NTILE() tương tự như hàm ROW_NUMBER(), nhưng thay vì gán các số liên tiếp cho các hàng liên tiếp tiếp theo, hàm xếp thứ tự cho các nhóm của bucket. Bucket là tập hợp của nhiều dòng liên tiếp và số lượng bucket được đặt làm tham số của hàm NTILE().
Ví dụ: NTILE(10) có nghĩa là tập dữ liệu sẽ được chia thành 10 nhóm bằng nhau.
Với ví dụ câu hỏi ban đầu, nếu query với hàm NTILE(10), hàm này sẽ chia tập dữ liệu thành 25 (số dòng trong bảng)/10 = 2,5. Tuy nhiên, vì kích thước của mỗi bucket cần phải là số nguyên nên giá trị này sẽ được làm tròn thành 3 và bucket cuối cùng chỉ có 2 hàng. Do đó, mỗi bucket sẽ có 3 dòng và được đánh số liên tiếp từ 1 đến 10.
SELECT
from_user,
COUNT() as total_emails, NTILE(10) OVER (ORDER BY count() desc)
FROM google_gmail_emails
GROUP BY from_user

Lưu ý: không nên sử dụng NTILE() để tính phần trăm, bởi hàm này chỉ chia kết quả trong các nhóm có kích thước bằng nhau và có thể xảy ra tình trạng các bucket có số lượng dòng khác nhau lại được xếp hạng như nhau. Vì vậy khi xử lý phần trăm, nên sử dụng PERCENT_RANK() thay thế.
Đọc thêm: JOIN của SQL là gì và cách dùng như nào?
2.3. Value Functions
LAG()
Hàm LAG() gán cho mỗi dòng một giá trị của dòng trước đó theo một thứ tự trong một partition. Nói cách khác, LAG() cho phép dịch chuyển bất kỳ cột nào xuống một dòng trong mỗi partition. Trong đó, nếu không xác định rõ offset (số giá trị bỏ qua tính từ trên xuống), tham số này bị bỏ qua và mặc định là 1.
Lấy ví dụ: Bảng sf_restaurant_health_violations chứa dữ liệu về số lượng vi phạm vệ sinh an toàn thực phẩm theo từng ngày. Làm thế nào để xác định phần trăm thay đổi (chênh lệch) giữa số lượng vi phạm của ngày hôm nay và ngày trước đó?
Để truy xuất dữ liệu để giải quyết bài toán, bạn có thể query:
SELECT
inspection_date::DATE,
COUNT(violation_id),
LAG(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE)
COUNT(violation_id) – LAG(COUNT(violation_id)) OVER( ORDER BY inspection_date::DATE) AS diff
FROM sf_restaurant_health_violations
GROUP BY 1

LAG() đã dịch chuyển giá trị của cột thứ 2 lùi một dòng theo ngày, ví dụ dòng thứ 2 ( 15/09/2015) không có 0 vi phạm nào trong khi ngày trước đó (08/09/2015), có 1 vi phạm. Lưu ý rằng do tính đặc thù của tập dữ liệu này nên không phải tất cả các ngày đều tồn tại trong bảng vì việc kiểm tra không diễn ra hàng ngày.
Khi sử dụng hàm LAG(), dòng đầu tiên trong partition sẽ luôn được gán giá trị NULL.
LEAD()
Hàm LEAD() ngược lại với hàm LAG(): trong khi LAG() trả về giá trị của dòng trước cho mỗi dòng, thì hàm LEAD() sẽ trả về giá trị của dòng sau. Nói cách khác, hàm LAG() lùi giá trị xuống 1 dòng, LEAD() sẽ dịch giá trị lên 1 dòng.
Nếu câu hỏi phía trên yêu cầu tính toán sự khác biệt giữa số lần vi phạm hiện tại và ngày tiếp theo, có thể giải quyết bằng cách sử dụng hàm LEAD() như sau:
SELECT
inspection_date::DATE,
COUNT(violation_id),
LEAD(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE),
COUNT(violation_id) – LEAD(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE) AS diff
FROM sf_restaurant_health_violations
GROUP BY 1

FIRST_VALUE()
FIRST_VALUE() gán giá trị đầu tiên trong partition, theo một số thứ tự xác định dòng nào sẽ là dòng đầu tiên.
Giả sử, bạn cần tính toán sự khác biệt giữa số lượng người dùng duy nhất của mỗi khách hàng (mỗi khách hàng khi truy cập website lại tạo ra một user ID khác nhau) giữa tháng phát sinh truy cập và tháng đầu tiên (tháng 2) từ bảng fact_events. Đầu tiên, cần lấy số user id của mỗi khách hàng trong một tháng bằng truy vấn:
SELECT
client_id,
EXTRACT(month from time_id) as month,
count(DISTINCT user_id) as users_num
FROM fact_events
GROUP BY 1,2

Tiếp theo, cần trừ số lượng user id của mỗi tháng phát sinh truy cập với số lượng user id của tháng Hai bằng cách sử dụng hàm FIRST_VALUE().
SELECT
client_id,
EXTRACT(month from time_id) as month,
COUNT(DISTINCT user_id) as users_num,
FIRST_VALUE(count(DISTINCT user_id)) OVER(
PARTITION BY client_id
ORDER BY EXTRACT(month from time_id))
FROM fact_events
GROUP BY 1,2

Hàm FIRST_VALUE() sẽ gán giá trị đầu tiên trong partition (giá trị users_num của mỗi client id trong các tháng) cho tất cả các dòng. Như vậy, cột first_value sẽ có giá trị users_num của desktop trong tháng 2 với tất cả dòng dữ liệu của desktop và tương tự với mobile.
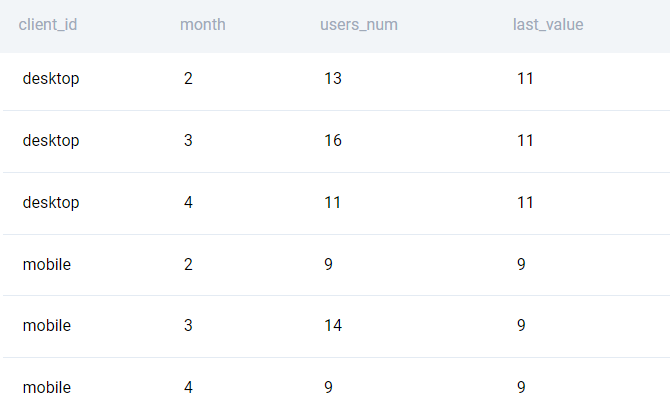
LAST_VALUE()
Hàm LAST_VALUE() trái ngược với hàm FIRST_VALUE(): hàm này trả về giá trị từ dòng cuối cùng của partition.
Ví dụ, nếu nhiệm vụ thứ hai trong câu hỏi phía trên không phải là tính sự khác biệt giữa tháng phát sinh truy cập và tháng đầu tiên khi có dữ liệu, mà là giữa tháng phát sinh truy cập và tháng cuối cùng khi có dữ liệu, có thể truy vấn dữ liệu:
SELECT
client_id,
EXTRACT(month from time_id) as month,
COUNT(DISTINCT user_id) as users_num,
LAST_VALUE(count(DISTINCT user_id)) OVER(
PARTITION BY client_id
ORDER BY EXTRACT(month from time_id))
FROM fact_events
GROUP BY 1,2
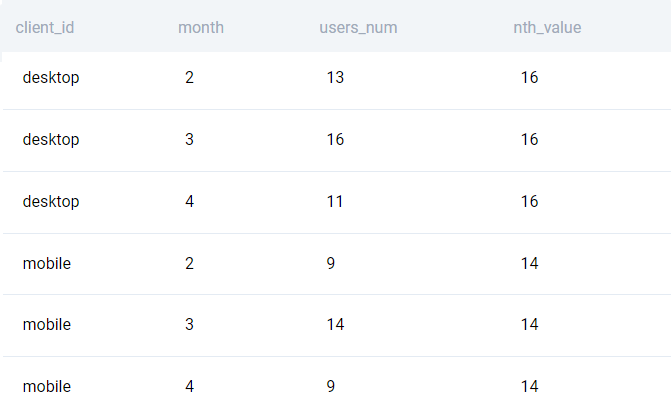
NTH_VALUE()
Hàm NTH_VALUE() có ý nghĩa khá giống với FIRST_VALUE() và LAST_VALUE(). Sự khác biệt là: trong khi FIRST_VALUE() và LAST_VALUE() xuất ra giá trị của dòng đầu tiên hoặc dòng cuối cùng của partition thì NTH_VALUE() cho phép người dùng xác định giá trị nào trong đơn dòng sẽ được gán cho các dòng khác.
Ví dụ, câu hỏi phía trên được thay đổi thành tính từ số lượng người dùng trong tháng dữ liệu thứ hai của partition (tháng 3):
SELECT
client_id,
EXTRACT(month from time_id) as month,
count(DISTINCT user_id) as users_num,
NTH_VALUE(count(DISTINCT user_id), 2) OVER(
PARTITION BY client_id)
FROM fact_events
GROUP BY 1,2
3. Một số syntax nâng cao trong SQL
Bên cạnh các window function phổ biến, SQL vẫn cung cấp một số hàm nâng cao nhằm hỗ trợ Data Analyst giải quyết các bài toán phức tạp, cụ thể:
- Frame;
- Mệnh đề EXCLUDE;
- Mệnh đề FILTER;
- Window chaining.
FRAME
Frame xác định những dòng nào được áp dụng cách tính của các hàm window functions, với mốc được tính từ dòng hiện tại.
Giả sử, bạn được yêu cầu giải một bài toán: Tìm tổng doanh thu trung bình động (rolling average) trong 3 tháng, từ một bảng dữ liệu về giao dịch với các trường là người dùng, số tiền giao dịch và ngày giao dịch. Kết quả được tính theo tháng (YYYY-MM).
Trong đó, trung bình động trong 3 tháng được xác định bằng cách tính tổng doanh thu trung bình từ tất cả các giao dịch mua hàng của người dùng trong tháng hiện tại và hai tháng trước đó.
Với câu hỏi trên, cho một bảng amazon_purchases chứa dữ liệu về các đơn hàng mua trên Amazon, với các trường dữ liệu liên quan như thời điểm tạo đơn hàng (created_at), số tiền giao dịch của mỗi đơn hàng (purchase_amt).
Để giải bài toán này, bước đầu tiên là tính tổng doanh thu mỗi tháng dựa trên bảng đã cho, có thể đạt được bằng cách sử dụng truy vấn sau:
SELECT
TO_CHAR(created_at::DATE, ‘YYYY-MM’) AS MONTH,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY TO_CHAR(created_at::DATE, ‘YYYY-MM’)
ORDER BY TO_CHAR(created_at::DATE, ‘YYYY-MM’)
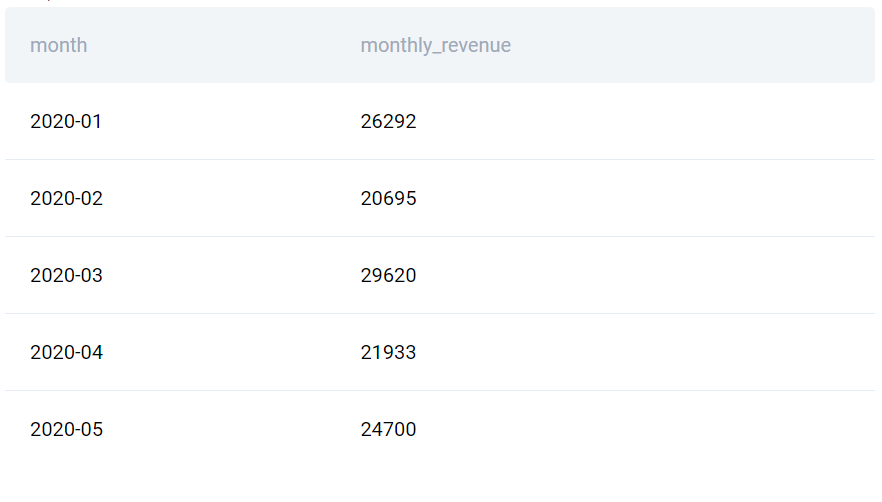
Sau đó, kết quả của truy vấn này có thể được sử dụng để tính trung bình động. Cách phổ biến và hiệu quả nhất để thực hiện điều đó là sử dụng hàm cửa sổ tổng hợp AVG() như sau:
SELECT
t.month,
AVG(t.monthly_revenue) OVER(
ORDER BY t.month ROWS BETWEEN 2 PRECEDING
AND CURRENT ROW) AS avg_revenue
FROM (
SELECT
to_char(created_at::date, ‘YYYY-MM’) AS MONTH,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY to_char(created_at::date, ‘YYYY-MM’)
ORDER BY to_char(created_at::date, ‘YYYY-MM’)
) t;
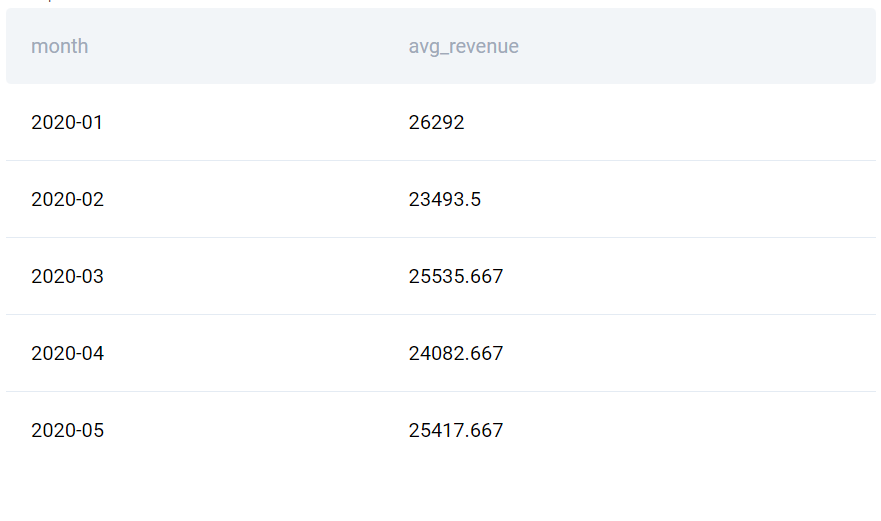
Trong query phía trên, ROWS BETWEEN 2 PRECEDING AND CURRENT ROW được gọi là frame. Lúc này, các window function sẽ chỉ tính toán giá trị trung bình dựa trên 3 dòng: 2 dòng trước và dòng hiện tại.
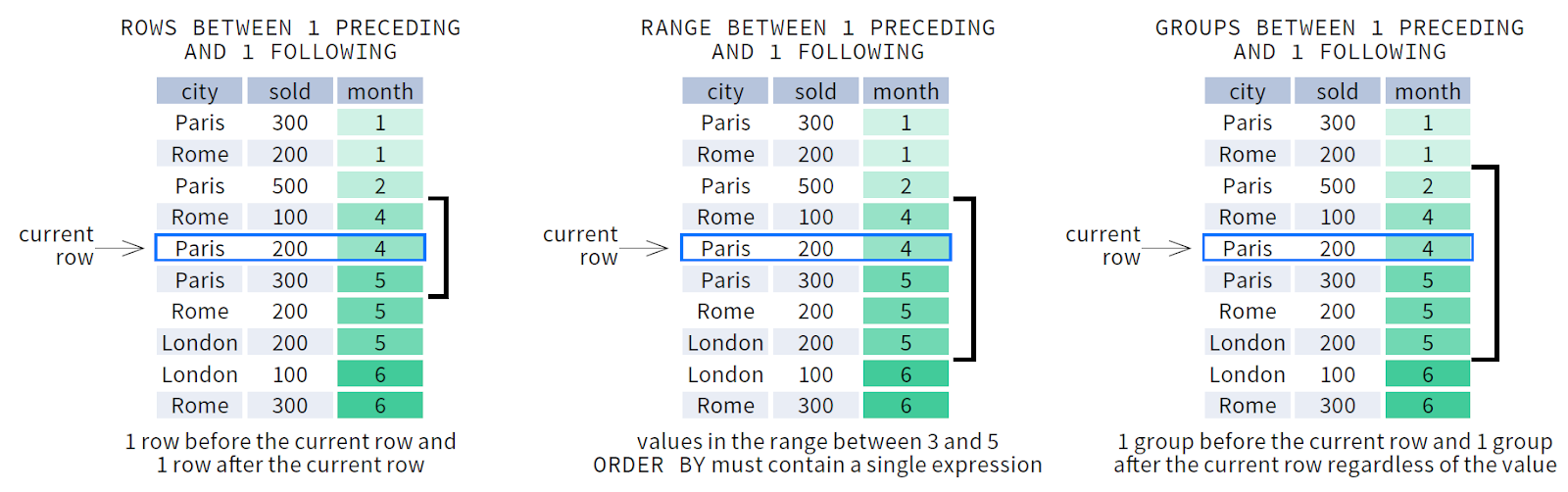
Có nhiều từ khóa có thể được sử dụng để xác định frame, bao gồm ROWS, GROUPS hoặc RANGE với syntax ROWS | RANGE | GROUPS BETWEEN lower_bound AND upper_bound.
Sự khác biệt của ROWS, RANGE và GROUPS được hiểu đơn giản:
- ROWS: đơn vị tính giới hạn theo hàng
- RANGE: đơn vị tính giới hạn theo khoảng giá trị đúng theo điều kiện
- GROUP: đơn vị tính giới hạn theo nhóm nhỏ hơn ngay sát dòng hiện tại và lớn hơn ngay sát dòng hiện tại
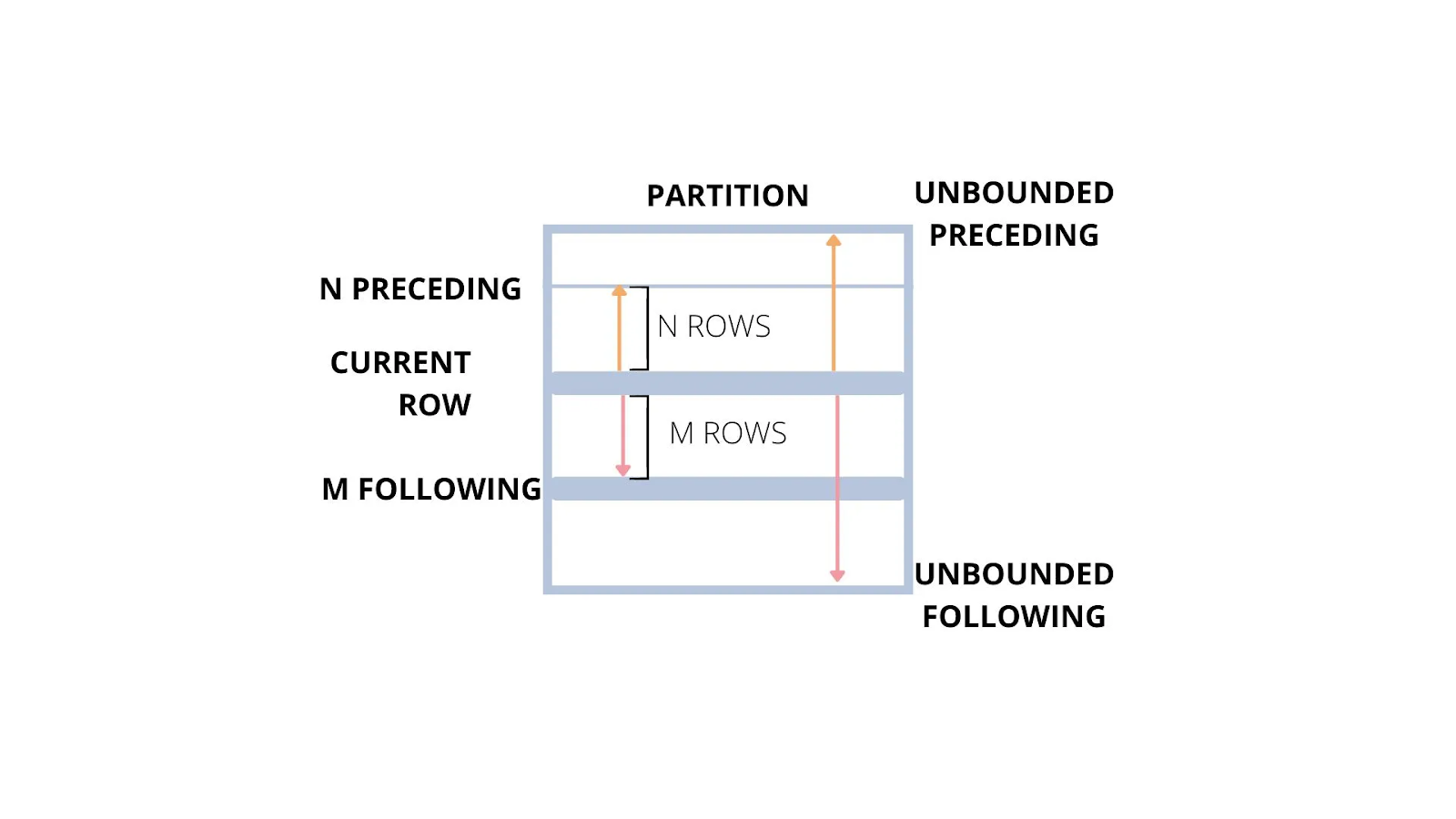
Trong đó lower_bound (giới hạn dưới) và upper_bound (giới hạn trên) bao gồm:
- UNBOUNDED PRECEDING – tất cả các dòng phía trước dòng hiện tại.
- n PRECEDING – n dòng phía trước dòng hiện tại.
- CURRENT ROW – dòng hiện tại.
- n FOLLOWING – n dòng phía sau dòng hiện tại.
- UNBOUNDED FOLLOWING – tất cả các dòng phía sau dòng hiện tại.
Lưu ý:
- Khái niệm frame (ROWS, RANGE, GROUPS) không được áp dụng với các hàm RANKING.
- Mặc định:
- Nếu window functions có ORDER BY, frame mặc định là RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
- Nếu window functions không có ORDER BY, frame mặc định là ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
EXCLUDE
Mệnh đề EXCLUDE có thể được đưa vào frame để loại trừ một số dòng theo điều kiện khi đưa vào partition. Giá trị mặc định là EXCLUDE NO OTHERS và không ảnh hưởng đến truy vấn.
Một số syntax khác của EXCLUDE là:
- EXCLUDE CURRENT ROW: loại trừ dòng hiện tại
- EXCLUDE GROUP: loại trừ nhóm dựa trên dòng hiện tại
- EXCLUDE TIES: tất cả các dòng có cùng giá trị với dòng hiện tại, ngoại trừ dòng hiện tại
Giả sử, mức trung bình động được tính bằng cách lấy mức trung bình của tháng trước và tháng sau. Cụ thể, giá trị của tháng 4 năm 2020 sẽ được tính bằng cách lấy giá trị trung bình từ doanh thu của tháng 3 và tháng 5 năm 2020:
SELECT
t.month,
monthly_revenue,
AVG(t.monthly_revenue) OVER(
ORDER BY t.month ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING EXCLUDE CURRENT ROW) AS avg_revenue
FROM (
SELECT
to_char(created_at::date, ‘YYYY-MM’) AS MONTH,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt>0
GROUP BY to_char(created_at::date, ‘YYYY-MM’)
ORDER BY to_char(created_at::date, ‘YYYY-MM’)
) t
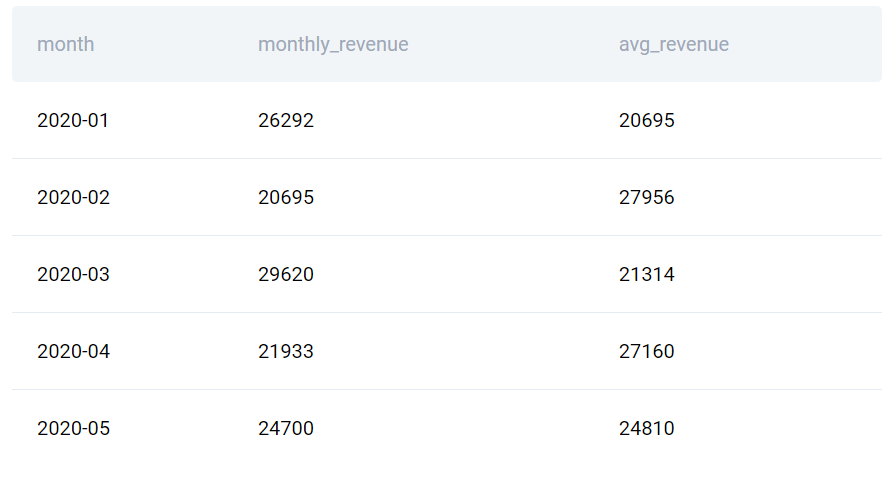
Mệnh đề OVER() trong window functions lúc này trở thành tất cả các dòng giữa dòng phía trên và dòng phía dưới của dòng hiện tại, trừ dòng hiện tại. Lúc này, giá trị trung bình động của tháng 4/2020 được tính bằng (29620+24700)/2 = 27160.
FILTER()
FILTER() cho phép xác định các điều kiện bổ sung để loại trừ một số dòng khỏi window function dựa trên một điều kiện nhất định.
Giả sử, với câu hỏi tính doanh thu trung bình động phía trên, nếu thay đổi cách tính vẫn dựa trên doanh thu từ tháng trước và tháng tiếp theo nhưng chỉ trong những tháng có doanh thu cao hơn 25000. Bạn có thể thêm điều kiện này bằng cách:
SELECT
t.month,
monthly_revenue,
AVG(t.monthly_revenue)
FILTER(WHERE monthly_revenue > 25000)
OVER(ORDER BY t.month ROWS BETWEEN 1 PRECEDING AND 1
FOLLOWING EXCLUDE CURRENT ROW) AS avg_revenue
FROM (
SELECT
to_char(created_at::date, ‘YYYY-MM’) AS MONTH,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
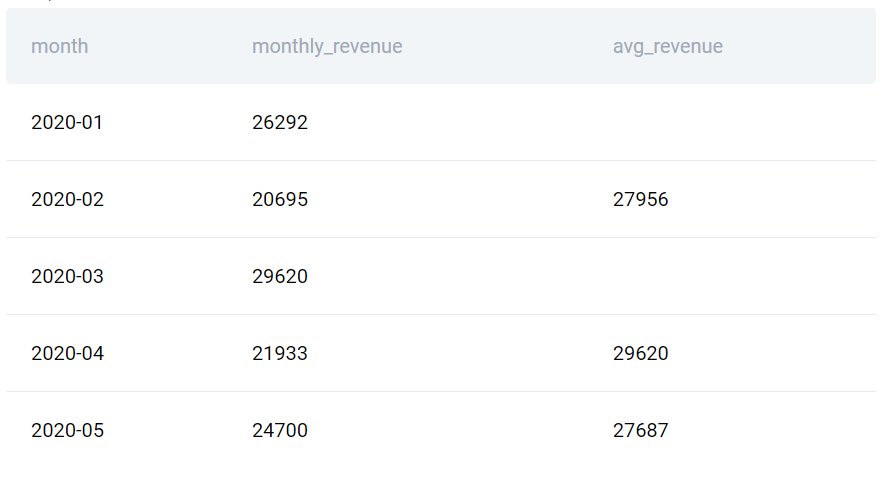
Từ kết quả truy vấn, có thể thấy không thể tính trung bình động cho tháng 3/2020 vì doanh thu trong cả tháng 2 và tháng 4 đều nhỏ hơn 25000.
WINDOW CHAINING
Window chaining giúp xác định một window có thể được ‘tái sử dụng’ trong nhiều window functions khác nhau, khái niệm này khá tương đương với Common Table Expressions (CTE).
Một window có thể được khai báo riêng biệt, được đặt tên và được sử dụng lại nhiều lần bằng cách chỉ chèn tên window vào đúng vị trí.
Lấy ví dụ về một câu hỏi của Amazon:
Từ một bảng lưu trữ dữ liệu số lượt mua hàng theo ngày, hãy tính phần trăm thay đổi trong doanh thu qua từng tháng. Kết quả được tính theo từng tháng (YYYY-MM) và phần trăm thay đổi được làm tròn đến dấu thập phân thứ 2, trong đó phần trăm thay đổi được tính bằng công thức ((doanh thu của tháng này – doanh thu của tháng trước) / doanh thu của tháng trước) * 100.
Table: sf_transactions
Bài toán này có thể được giải với query:
SELECT
TO_CHAR(created_at::DATE, ‘YYYY-MM’) AS year_month,
ROUND(
(100 * (SUM(value) – LAG(SUM(value), 1)
OVER (ORDER BY TO_CHAR (created_at::DATE, ‘YYYY-MM’)))
/ (LAG(SUM(value), 1)
OVER (ORDER BY TO_CHAR (created_at::DATE, ‘YYYY-MM’))))
, 2) AS revenue_diff_pct
FROM sf_transactions
GROUP BY year_month
ORDER BY year_month ASC
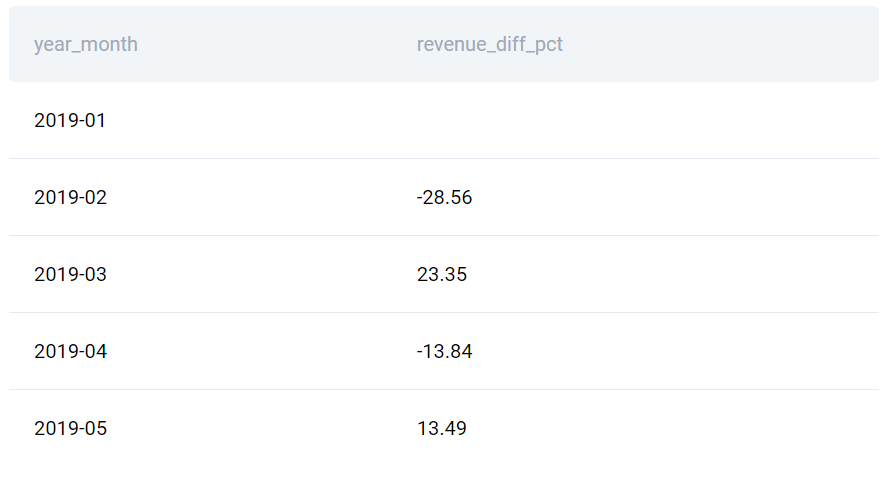
ORDER BY to_char(created_at::date, ‘YYYY-MM’) lặp lại đã khiến query nhìn khá lộn xộn và khó đọc. Thay vì vậy, chúng ta có thể sử dụng window chaining bằng cách:
SELECT
TO_CHAR(created_at::DATE, ‘YYYY-MM’) AS year_month,
ROUND(
100 * ((SUM(value) – LAG(SUM(value), 1) OVER w)
/ (LAG(SUM(value), 1) OVER w))
, 2) AS revenue_diff_pct
FROM sf_transactions
GROUP BY year_month
Tạm kết
Hy vọng bài viết trên đã giúp bạn trang bị tổng quan hiểu biết về cách sử dụng của các hàm window functions cơ bản trong SQL. Window functions rất quan trọng và được sử dụng nhiều trong việc truy xuất dữ liệu.
Để sử dụng thành thạo window functions đòi hỏi phải thực hành nhiều lần, mà ngay cả nếu chỉ biết syntax và câu lệnh thuần thì Data Engineer/Data Analyst vẫn sẽ gặp khó khăn, đặc biệt nếu không có kiến thức về cơ sở dữ liệu, không biết mình có những dữ liệu nào, bảng nào, ở đâu, mối quan hệ giữa các bảng, các luồng data pipeline được thiết kế ra sao,… Việc thiếu những kiến thức này không những khiến cho các bạn gặp khó khăn trong quá trình phân tích, mà còn hạn chế khả năng phát triển nếu muốn thăng tiến xa hơn với những vị trí Data.
Để trang bị kiến thức về hệ thống dữ liệu và hiểu được cấu trúc của dữ liệu trong hệ thống từ đó truy vấn dữ liệu hiệu quả hơn, tham khảo ngay khóa học SQL for Data Analysis!

Bài viết được biên dịch từ stratascratch.com, xin vui lòng không sao chép dưới mọi hình thức!








