

Biến đổi dữ liệu (data transformation) là quá trình chuyển đổi dữ liệu thô thành một định dạng hoặc cấu trúc phù hợp hơn cho việc xây dựng mô hình và khám phá dữ liệu. Đây là một bước quan trọng trong kỹ thuật xử lý biến (feature engineering). Trong bài viết này, TM Data school sẽ trình bày các kỹ thuật biến đổi dữ liệu gồm: log transformation, clipping method, và data scaling. Nhưng trước tiên hãy cùng giải đáp một số câu hỏi quan trọng về Why & When:
Tại sao cần biến đổi dữ liệu (Why)?
- Thuật toán có nhiều khả năng bị sai lệch khi phân phối dữ liệu bị lệch về tỉ lệ/ đơn vị đo… (scale).
- Biến đổi dữ liệu về cùng một tỷ lệ cho phép thuật toán so sánh mối quan hệ tương đối giữa các điểm dữ liệu tốt hơn.
Khi nào nên áp dụng biến đổi dữ liệu (When)?
Khi triển khai các thuật toán supervised learning, dữ liệu huấn luyện (training data) và dữ liệu kiểm tra (test data) cần được biến đổi theo cùng một cách. Đây gần như là bước mặc định và cần tiến hành trước khi bước vào quá trình training.
Và bây giờ chúng ta sẽ cùng đi vào 2 nội dung chi tiết của bài viết về feature engineering và data transformation nhé. Còn nếu bạn muốn thực hành các kỹ thuật trên với các project thực tế dưới sự hướng dẫn của các trainer giàu kinh nghiệm, hãy tham gia khóa học Advanced Analytics with Python của TM Data school với 100% giảng viên được đào tạo về Data science tại nước ngoài.
1. Basic Feature Engineering và EDA (Exploratory Data Analysis)
Trong bài viết này, TM Data school sẽ dùng dữ liệu Marketing từ Kaggle. Đầu tiên, chúng ta cần thực hiện một số kỹ thuật xử lý biến cơ bản để làm cho dữ liệu gọn gàng và sẵn sàng cho quá trình training.

1.1 Chuyển đổi năm sinh thành “Tuổi”
Trừ năm hiện tại cho Year_Birth.
1.2 Chuyển đổi ngày khách hàng đăng ký (“Dt_Customer”) thành “Enrollment_Length”
Khá tương tự như trên, chúng ta cần lấy ra dữ liệu với đơn vị “năm” (xem python code phía trên).
1.3 Chuyển đổi biến tiền tệ (“Income”) thành dữ liệu dạng số (“Income_M$”)
Bước này bao gồm bốn bước:
1) Làm sạch dữ liệu bằng cách loại bỏ các ký tự “, $ .”;
2) Thay thế giá trị null bằng 0 (sẽ có nhiều cách xử lý null khác tuy nhiên trong ví dụ này chúng ta sẽ chọn cách này để đơn giản hoá);
3) Chuyển đổi data type từ “string” thành “integer”;
4) Scale data nhỏ lại thành triệu đô.
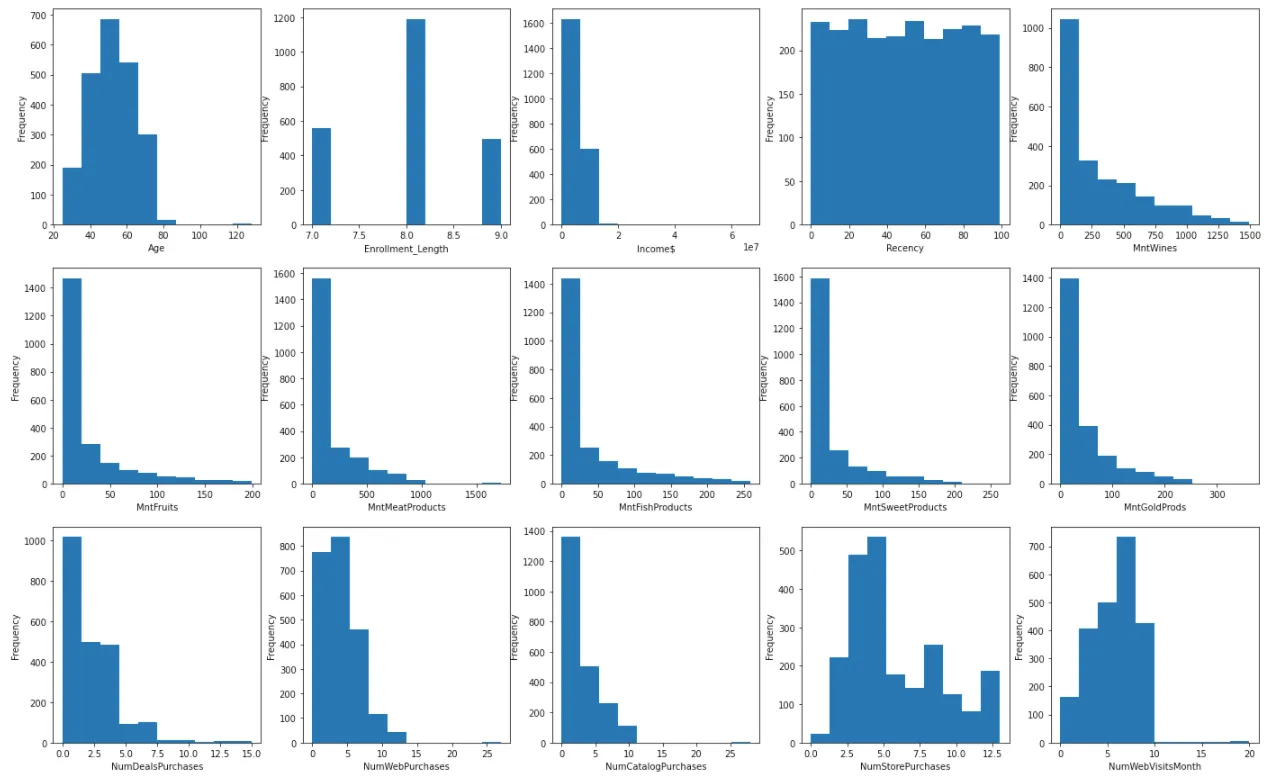
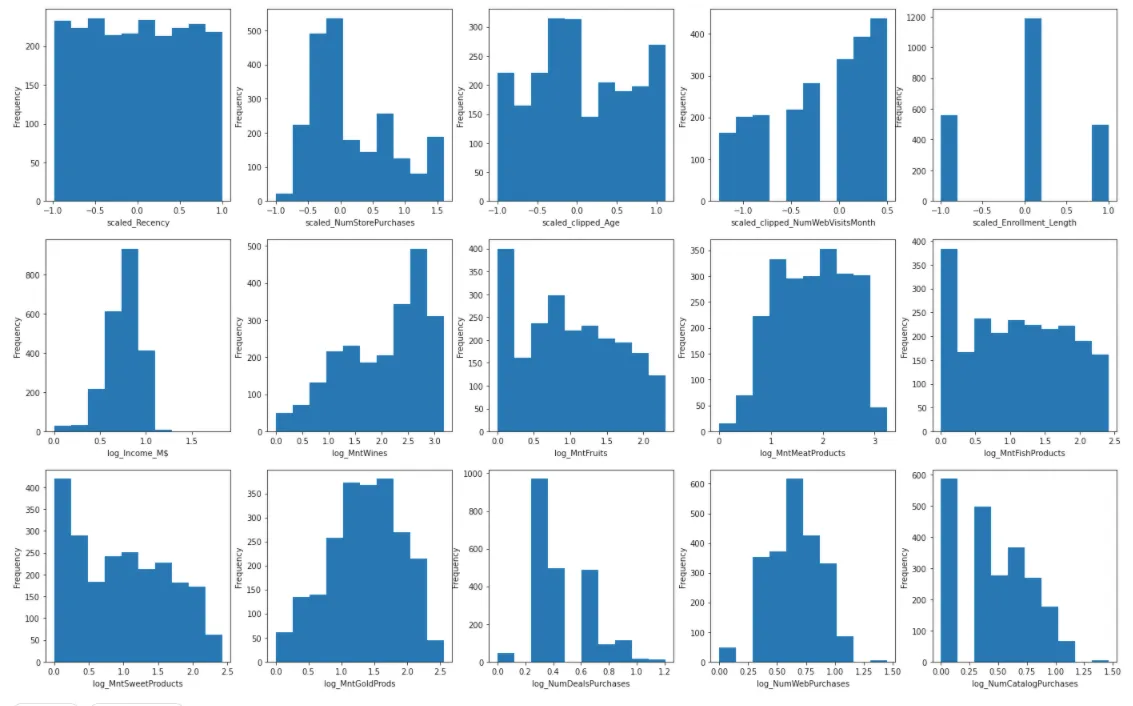
Sau đó chúng ta sẽ vào quá trình trực quan hoá (EDA) để khám phá tính phân phối của các biến. Việc này giúp định hướng cho phương pháp data transformation được lựa chọn ở phía sau.

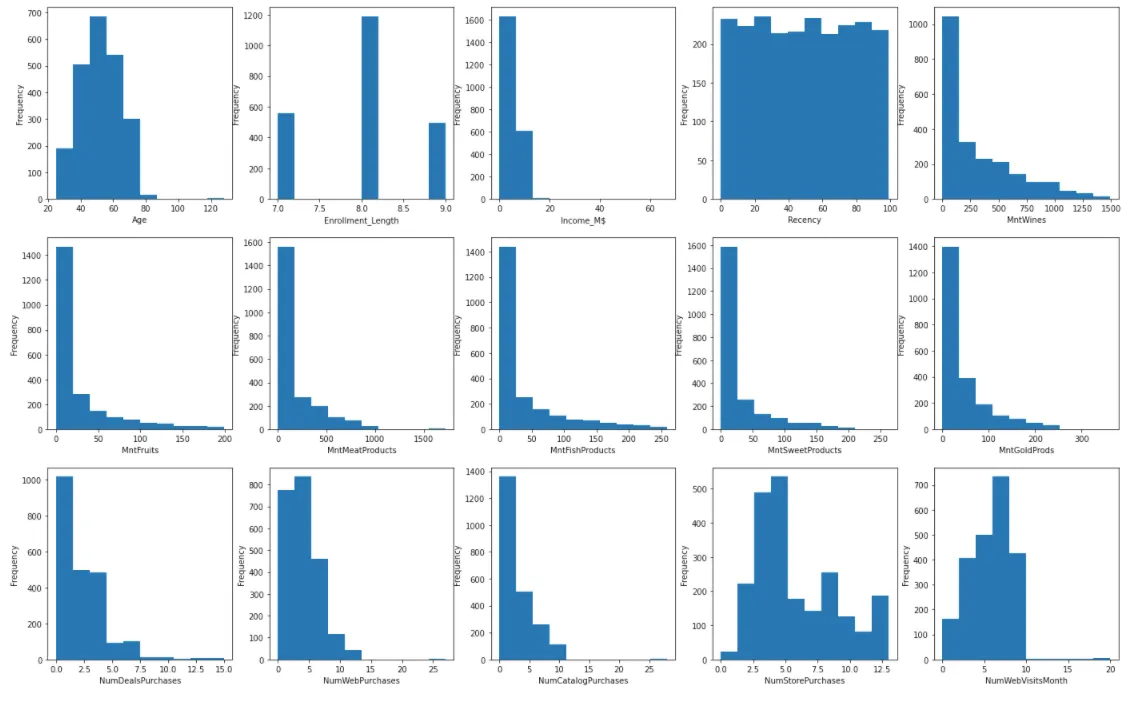
2. Tìm hiểu 3 kỹ thuật Data transformation phức tạp (thuộc feature engineering)
2.1 Biến đổi Logarit với dữ liệu lệch phải
Chúng ta có thể biến đổi các feature có phân phối lệch phải thành phân phối chuẩn với log scaling. Để đạt được điều này, chúng ta chỉ cần sử dụng hàm np.log(). Trong tập dữ liệu này, hầu hết các biến thuộc loại này.
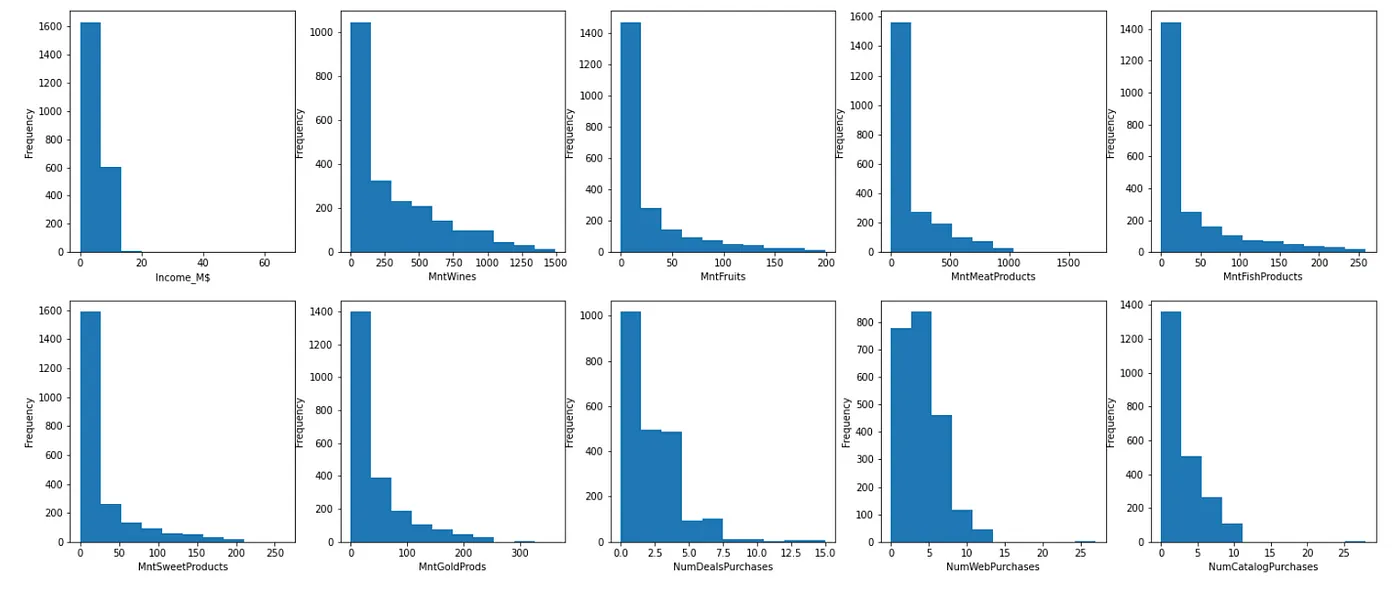

Dưới đây là kết quả sau log scaling. Các dữ liệu đã phân phối chuẩn hơn so với ban đầu. Lưu ý rằng dữ liệu phân phối chuẩn là điều kiện quan trọng để các thuật toán machine learning chạy hiệu quả, đặc biệt là các thuật toán dựa trên giả định rằng dữ liệu đầu vào tuân theo phân phối chuẩn, chẳng hạn như linear regression, logistic regression, và phân tích thành phần chính (PCA).
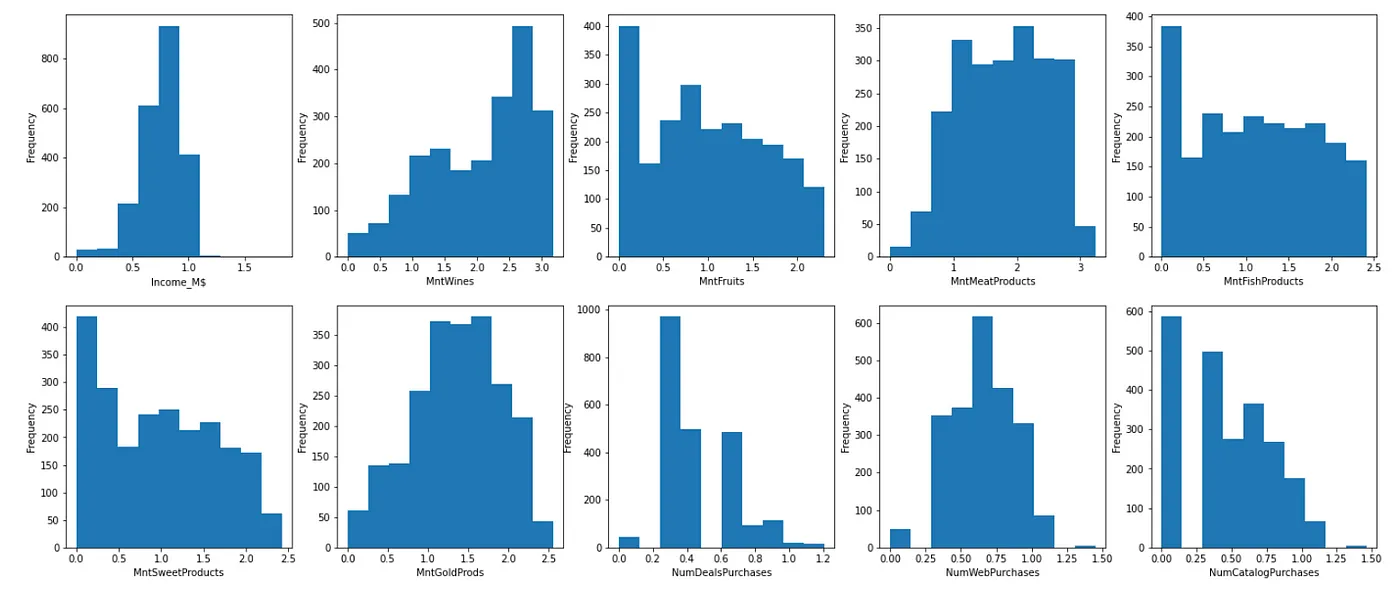
2.2 Kỹ thuật clipping để xử lý các giá trị ngoại lai (outlier)
Phương pháp này phù hợp khi có các giá trị ngoại lai trong tập dữ liệu. Để phát hiện tệp có nhiều giá trị ngoại lai không, chúng ta có thể kiểm tra ở bước EDA (xem từ các biểu đồ histogram). Phương pháp clipping đặt giới hạn trên và giới hạn dưới, và tất cả các điểm dữ liệu sau transform sẽ được chứa trong phạm vi đó.
Chúng ta có thể sử dụng quantile() để tìm ra phạm vi của phần lớn dữ liệu (giữa phân vị 0.05 và phân vị 0.95). Bất kỳ giá trị nào dưới giới hạn dưới (được xác định bởi phân vị 0.05) sẽ được làm tròn lên giới hạn dưới. Tương tự, các số trên giới hạn trên (được xác định bởi phân vị 0.95) sẽ được làm tròn xuống giới hạn trên.

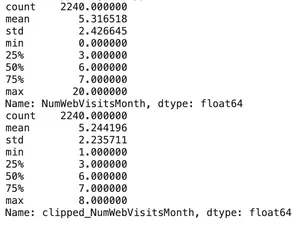
Từ biểu đồ histogram trong quá trình EDA, chúng ta có thể thấy rằng biến “Age” và “NumWebVisitsMonth” có các giá trị ngoại lai với các số lớn bất thường. Vì vậy, chúng ta sẽ áp dụng kĩ thuật clipping cho hai cột/ feature (biến) này.
Kết quả là, giá trị max cho cả hai feature trên giảm đáng kể:
- Age: từ 128 xuống 71
- NumWebVisitMonth: từ 20 xuống 8
2.3 Biến đổi Chia tỷ lệ (Scaling Transformation)
Sau khi biến đổi logarit và xử lý các giá trị ngoại lai, chúng ta có thể sử dụng thư viện scikit-learn preprocessing để chuyển đổi dữ liệu thành cùng một tỷ lệ. Thư viện này chứa một số hàm hữu ích: min-max scaler, standard scaler và robust scaler. Mỗi scaler phục vụ một mục đích khác nhau.
Min Max Scaler – Chuẩn hóa: MinMaxScaler() thường được áp dụng khi tập dữ liệu không bị lệch nhiều. Nó chuẩn hóa dữ liệu thành một phạm vi từ 0 đến 1 dựa trên công thức:

Standard Scaler – Chuẩn hóa tiêu chuẩn: Chúng ta sử dụng kỹ thuật này khi tập dữ liệu tuân theo phân phối chuẩn. StandardScaler() chuyển đổi các số thành dạng tiêu chuẩn với giá trị trung bình (mean) = 0 và phương sai (variance) = 1 dựa trên công thức z-score:

Robust Scaler: RobustScaler() phù hợp hơn cho tập dữ liệu có phân phối lệch và nhiều giá trị ngoại lai vì nó biến đổi dữ liệu dựa trên trung vị (median) và khoảng phân vị (quantile):

Để so sánh cách hoạt động của ba cách trên, chúng ta hãy cùng thử chúng nhé (sử dụng quá trình iteration) cho cả 3 loại StandardScaler(), RobustScaler(), MinMaxScaler().

Các scaler không thay đổi hình dạng của phân phối dữ liệu mà thay đổi độ trải rộng của các điểm dữ liệu (spread out).
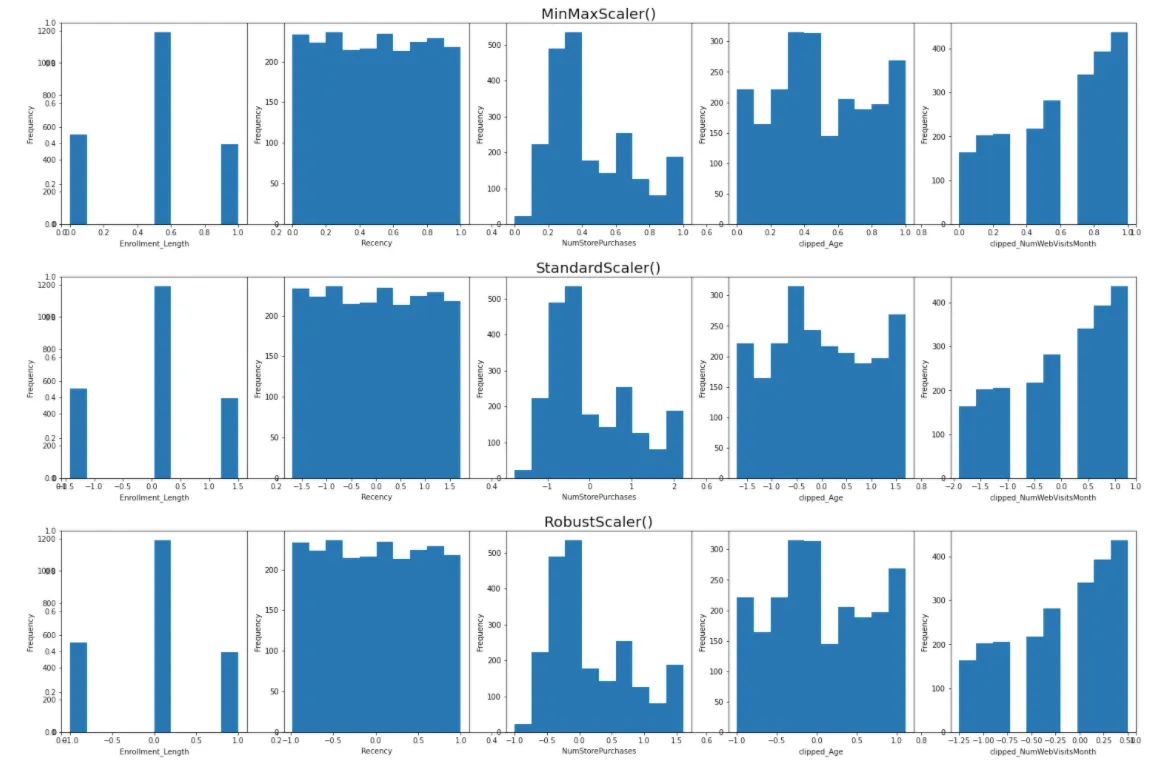
Lấy “NumStorePurchases” làm ví dụ, MinMaxScaler() chuyển đổi các giá trị thành nằm trong khoảng từ 0 đến 1, StandardScaler() chuyển đổi tập dữ liệu thành mean = 0 trong khi RobustScaler() chuyển đổi tập dữ liệu với median = 0.
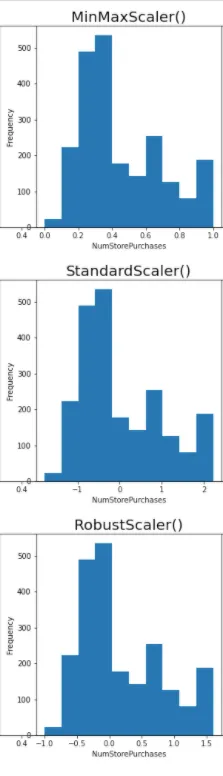
Trong tập dữ liệu này, các biến không bị lệch, đồng thời cũng không phân phối chuẩn, do đó việc chọn MinMaxScaler() trong số ba scaler này.
Bây giờ tất cả các feature (biến) đã được biến đổi và sẵn sàng cho quá trình training phía sau.
Trước transformation:
Sau transformation:
Ngoài 3 kĩ thuật log transformation, scaling, và clipping (để xử lý outlier) đã đề cập trong bài viết, chúng ta có thể sử dụng các kĩ thuật khác như one hot encoding (biến dữ liệu categorical thành numerical), hay imputation (xử lý missing values). Do bài viết đã tương đối dài, TM data school sẽ đề cập tới 2 kỹ thuật này ở một bài viết khác nhé.
Hy vọng qua bài viết này TM Data school đã cung cấp một cách dễ hiểu các kiến thức cơ bản về Feature Engineering và Data transformation. Nếu bạn muốn thực hành các kĩ thuật trên với các project thực tế dưới sự hướng dẫn của các trainer giàu kinh nghiệm, hãy tham gia khóa học Advanced Analytics with Python của TM Data school với 100% giảng viên được đào tạo về Data science tại nước ngoài (top 1% các chương trình về Data science trên thế giới) nhé.









